xLSTM - Faster in Training and Inference
Welcome to the forefront of Artificial Intelligence — introducing xLSTM. Developed by the visionary AI mastermind, Sepp Hochreiter, in collaboration with NXAI and the JKU Linz, xLSTM sets a new standard by offering significantly enhanced efficiency and performance in training and inference.
Faster
Faster
Energy efficient
Energy efficient
Cost effective
Cost effective
xLSTM defines a new class of AI architectures
It unites efficiency and performance, disrupting the Transformer dominance that has shaped the last decade of AI. Unlike traditional Transformer models, xLSTM delivers linear compute growth instead of quadratic, resulting in substantial energy savings — often by an order of magnitude. This innovation enables faster inference, lower latency, and dramatically improved cost-efficiency, all while maintaining or surpassing Transformer-level accuracy across benchmarks.
xLSTM architecture scales linearly, has constant memory complexity, advanced in-context learning and higher energy efficiency.

xLSTM architecture scales linearly, has constant memory complexity, advanced in-context learning and higher energy efficiency.
Superior Training Efficiency
When training within fixed FLOP budgets, xLSTM models consistently achieve better performance. Conversely, when targeting a fixed validation loss, xLSTM requires significantly fewer FLOPs, making it more efficient to train without compromising precision or generalization. Read our Scaling Laws paper.
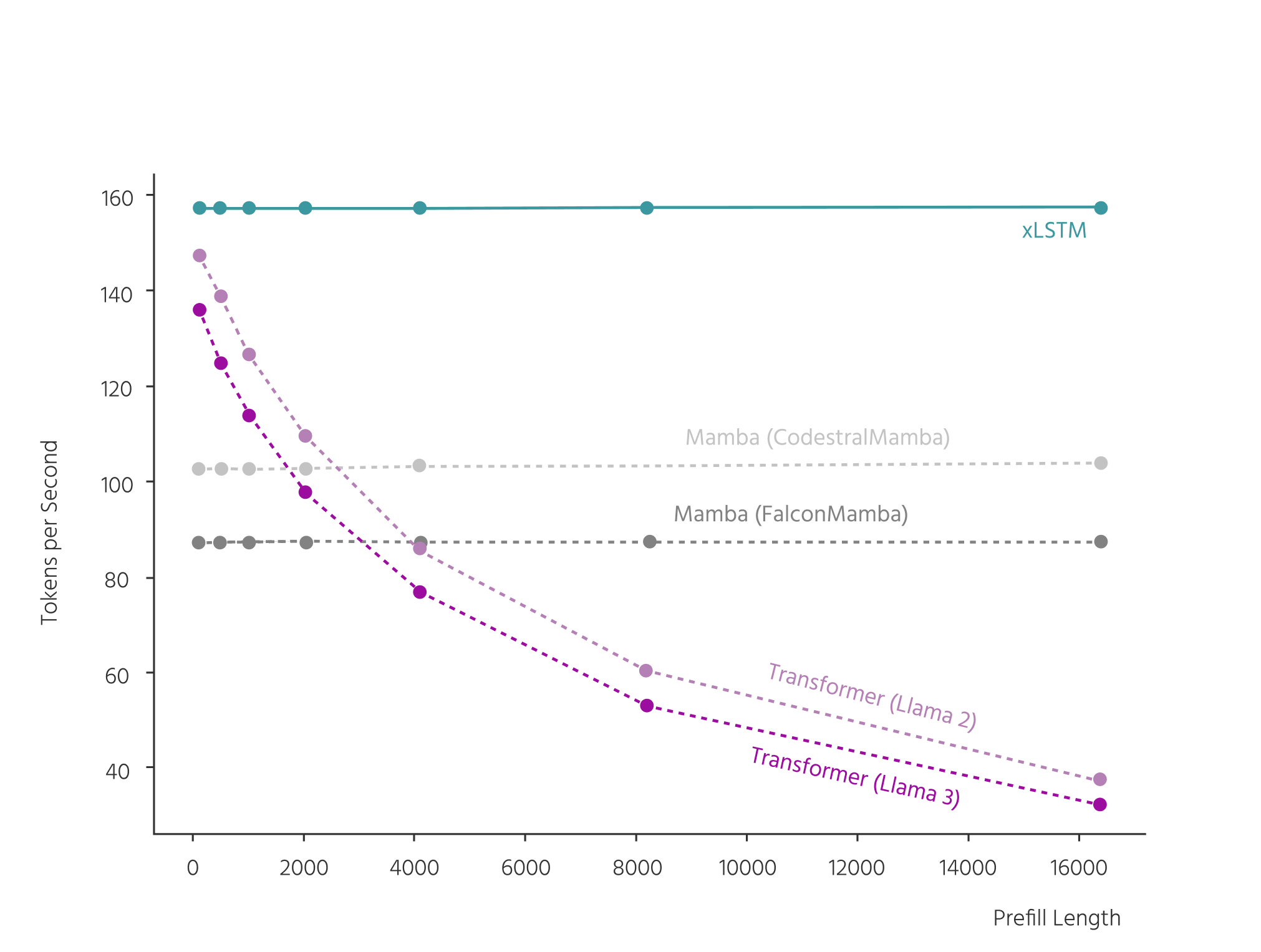
Unmatched Inference Performance
Across all inference benchmarks, xLSTM models are faster, more energy-efficient, and more cost-effective than their Transformer counterparts — delivering the same or better performance with a fraction of the computational demand.
A Foundation for European Digital Sovereignty
As Europe’s first home-grown foundation architecture, xLSTM is more than a technical achievement — it’s a strategic milestone for digital sovereignty. Designed for versatility, xLSTM’s capabilities extend far beyond language processing, excelling across a wide range of AI domains.
xLSTM is changing AI. Thanks to its performance and efficiency, we can better predict time series, optimise Agentic AI workflows and make robots work better.



Our Domains
xLSTM demonstrates its strengths in various domains. We are currently focusing on the areas of time series, robotics and agentic AI workflows. We build xLSTM models for companies, giving them a competitive advantage in terms of performance, costs and efficiency.

Prof. Dr. Sepp Hochreiters explains his xLSTM approach at Hannover Messe in 2025. © Deutsche Messe AG
xLSTM Roots
Prof. Dr. Sepp Hochreiter is one of the fathers of modern deep learning. With LSTM (Long Short-Term Memory), he laid the foundation in the 1990s for many developments in recent years. Now, with xLSTM, he is demonstrating another step forward in development.
xLSTM introduces three core architectural innovations:
Exponential Gating for dynamic information control
Matrix Memory & Covariance Update for long-term storage
Memory-Independent Update enabling true linear-time operation
These advances transform LSTM into a scalable architecture competitive with, and in many settings superior to, Transformers.
Explore our xLSTM Research
xLSTM Paper
Vision-xLSTM Paper
xLSTM: A Large Recurrent Action Model for robotics
Tiled Flash Linear Attention
Bio-xLSTM
xLSTM 7B model
FlashRNN
TiRex: Time Series
xLSTM Scaling Laws
Want to collaborate?
We work with you to make your processes more competitive, efficient and future-proof. Secure your competitive edge with xLSTM.